
Cobre
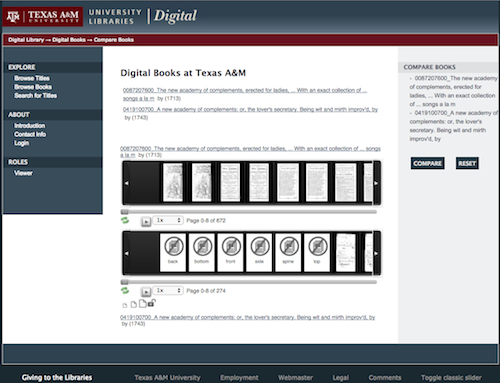
Cobre is a robust image comparison environment, presenting versions of texts in filmstrip view along side each other and
collating these images of different texts while allowing users to adjust the collation.
Cobre was originally created for Primeros Libros, but has been modified for the Early Modern OCR
Project (eMOP) to add the following features:
- Add the possibility for transcription of pages on the Annotations window;
- Make editable specific items of the metadata format on the Book Overview
page, adding Dublin Core font categories; - Make it easier for people to manually transcribe pages for particular (“local”)
editions and then share those transcriptions with other editions.
Using the Cobre tool, experts can:
- Determine which font(s) the document was originally printed in edit the
metadata; - Look at multiple copies of editions of the text to replace particular page
images that are readable with those that are not, making what we call a “Frankenbook”—a
book that didn’t really exist but that resembles what
did exist more closely than what we have got. This book is saved separately
from all editions and carefully distinguished from real-live documents, its
output only used for data-mining and not archival purposes, and saved in D-
Space under the scholar’s name so that others can check this revision and
OCR history, visible in “The Repository View”; - Type unreadable pages into a Transcription box that will appear in each
page Annotation window; - Correct the metadata.
Try the Cobre tool created for font identification and edition making in eMOP: mellon-cobre.library.tamu.edu/.
Currently there are several pre-ingested EEBO docs with multiple-editions.
You can access the open-source code for eMOP's Cobre tool on github: github.com/Early-Modern-OCR/Cobre
