
Special Characters, Unicode, and Early Modern English
With a dataset of 45 million page images, the eMOP team is dealing with a lot of text output, and that means dealing with Unicode. As an early modern English project, we're also working with ligatures and other special characters specific to the period, and that means considering the MUFI (the Medieval Unicode Font Inititiave).
Early modern printing culture was like the wild west; printers and publishers wrote their own rules. Punch-cutters (those who created the small metal punches from which type was cast, which was then used to apply ink to paper in a printing press), were more or less free to create characters and combinations of characters as they saw fit. Some characters were holdovers from pre-print conventions (using a macron to indicate that letters were left out), some were dictated by technological limitations (the long-s), some were dictated by practicality (using ligatures like ſt to combine common letter combinations into one punch), and some were matters of style (the plethora of different ampersand characters of the era). The individualized nature of typeface sets, which were hand-crafted by specialized artisans, means that we were unable to predict with certainty every character that would be present in our collection of 45 million pages images to be OCR'd.
Moreover, many of these ligatures and other special characters are no longer used widely in modern printing. Unicode is an industry standard for the encoding of text in a digital environment. It is capable of representing over 1 million separate characters or glyphs, but the current Unicode Standard set consists of some 110,000 glyphs from 100 different world scripts. As a modern creation, the Unicode Standard set does not include many of the special characters and ligatures that we have identified in our corpus of documents. This is where MUFI comes in. The Medieval Unicode Font Initiative, which is not limited to Medieval glyphs, is a non-profit workgroup created to address the absence of pre-modern print and hand-written characters in the Unicode Standard. As such, MUFI has been assigning unused Unicode values (called codepoints) to these special characters and is petitioning the Unicode Consortium for the inclusion of these assignments to the Unicode Standard.
Until then, however, eMOP has to work with both sets of values. Because OCR engines have to be trained to recognize the characters they will encounter on a page image, the issue of assigning Unicode values to a particular glyph is important to the eMOP project. This involves "showing" the engine images of a glyph, and then telling it what character that glyph represents. These character values are expressed with Unicode codepoints, and the resulting sets of training are referred to as "classifiers".
For example,  = r (lower-case, latin) = 0072 (Unicode codepoint in hex) = &[#114]; (entity value in decimal)
= r (lower-case, latin) = 0072 (Unicode codepoint in hex) = &[#114]; (entity value in decimal)
Note: In the example above the entity value should NOT include the '[' and ']' characters in it. They are there to prevent the browser from displaying the entity value as 'r'. Also, note that 0072 is a hexadecimal value that is equivalent to 114, a decimal value. For the entity value you could therefore use &[#x72]; as well, to also represent 'r'.
Creating classifiers for characters represented in the Unicode Standard set is fairly straightforward. Just about every browser, editor, or tool that displays text data is able to render the characters represented in the Unicode Standard set via standardized encoding schemes like UTF-8, UTF-16, etc. But how should eMOP encode special characters that are not defined in the standard set and cannot be rendered in a text editor? MUFI has created a character database that contains nearly every special character we have encountered in our document corpus, to date. We have elected to use that database to get established, but non-standard, Unicode codepoints for special characters that we find. And then we can use those codepoints to create classifiers for those glyphs while training our OCR engine(s).
Let's look at an example. In the excerpt from a page image of text below: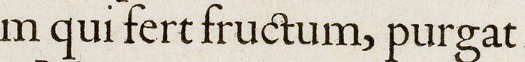
The ct ligature in the word fructum is a special character not defined in the Unicode Standard set. In the MUFI database I can click on 'c' in the menu and scroll down until I find this ligature.
I can see from the table that MUFI has assigned hex codepoint EEC5 to this particular ct ligature. EEC5 is a Unicode codepoint that has not officially been assigned to any character, but MUFI has assigned it to ct. Just having a codepoint value, however, is not enough. The OCR engine needs to have a UTF-8 encoded character to which it can assign a "cutout" of the image of this ct ligature.
To get a copy of the UTF-8 representation of this character I need to be able to cut-and-paste it from some other source. I have found a webpage called the Unicode Range Viewer created by Russell Cottrell to be an excellent tool for this. I can put eec5 in the search box on this page. Then in the table I just find column 'EEC' and scroll down to row 5.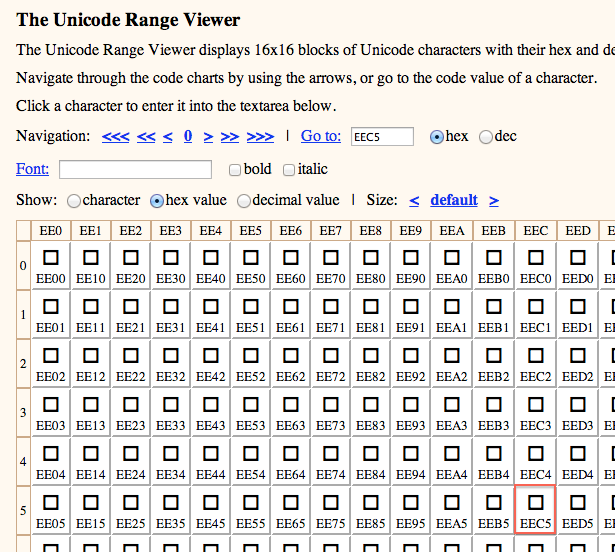
If I click on the box in the red square, it will paste that glyph into a text box at the bottom of the page. I can scroll down to copy that glyph and then paste it into a text file, which the OCR engine can use to identify the character during training.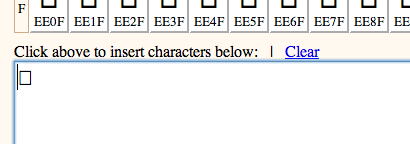
As you can see, (&[#xEEC5];) cannot be rendered properly in a browser or text editor, because this character is not defined in UTF-8—the tool does not know how to "draw" it. Depending on the tool and platform, you will see a blank box, a box with and X in it, a ? or some other symbol. It depends on what glyph that tool/platform has decided to use to render undefined characters.
eMOP and Training Tesseract
As noted in an earlier post about Training with Tesseract for eMOP, we have developed our own tool called Franken+ to create training for the Tesseract OCR engine. One of the final stages in the Franken+ training process is to use the glyphs we've identified in our training typeface, to create "franken-pages"—the images of the glyphs we've identified are used to recreate a base text as a set of page images in .tif format. This base text must include UTF-8 character renditions of every glyph, whether defined in the Unicode Standard set or not, that is identified via Franken+. This ensures that any special characters found in our training pages are included in the files used to create Tesseract classifiers. We added these special characters to our base text using the method described above.
In our work so far we had identified about 75 special characters. We also contacted our friends and collaborators at PRImA Research who had worked on the earlier IMPACT project to OCR early modern texts in Europe. They were able to supply us with a list of almost 200 special characters that they had identified in their project, which we promptly added to our base text. (They have since, been kind enough to update their list with an additional 7 characters that we identified.) Our resulting base text is a text file which contains 10,644 words and at least two examples of nearly 200 special characters indicative to the early modern print period.
Please feel free to view and download our base text used to train Tesseract via Franken+.
