
Testing with Tesseract
Testing with Tesseract:
Once we had our training completed we need to do some testing before going into limited, then full-scale production mode. We have 45 million page images to scan.
With the emop.traineddata file moved to the tessdata/ folder, you can issue the command to run Tesseract, trained with your font, on any page image file. In our case all page images are .tif files. Supposedly, .bmp and .png files will also work, but NOT .jpg files.
When Tesseract is installed it adds the path to the tessdata/ folder to your PATH, so you can issue the command from any directory on your test machine.
Currently, I am moving the page images to be scanned into the appropriate <font>/Training/attempt<#>/ folder so that the output files will be placed there as well. But as we move to larger scale testing, I think that will have to change. We could just create testing folders with page images in them and run Tesseract from there by adding a path to the appropriate attempt<#>/ folder to the <output> parameter.
The command is:
tesseract <pgImg> <output> [-l <lang>] [<configfile>]
where:
- <pgImg> is the name of a single .tif file
- <output> is the path and file name of the output file (do not include a file extension; Tesseract will add one for you based on the output type it creates)
- <lang> is the name of the language you created while training. In our case, “emop”
- <configfile> is the path and filename to a file you create that contains configuration information<link>
The parameters in the [] are optional. If you run Tesseract without the –l <lang> parameter, then Tesseract will run with its default settings, i.e. no training. This is equivalent to the using the <eng> language which is Tesseract’s default and is installed in tessdata/ automatically. You can have multiple <lang>.traineddata files in your tessdata/ folder and just specify which you want to use with the –l option.
Ambiguous Characters:
Tesseract has a mechanism that allows users to try to help Tesseract with consistent substitution errors that it makes while OCRing. I found that I could only start using this functionality once I got the error rate down to a point where I could start to see patterns in the errors Tesseract was making both within and across documents. Once I got to that point I was able to utilize the .unicharambigs file to “help” Tesseract to correct some of the consistent substitution errors it was making. For instance seeing an ‘m’ as ‘rn’ or turning ‘r’s into ‘t’s.
The name of the file is <lang>.unicharambigs and the format is:
emop.unicharambigs 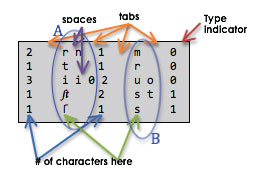
the type indicator is a value from 0 to 4, but I’ve only ever used 0 or 1. I’m not sure what 2-4 do.
- The substitution of the concatenated values of B are not necessarily made for A.
“Instead it acts as a hint that if the substitution turns a word from a non-dictionary word into a dictionary word, that the word should not be used to train the adaptive classifier, and the segmentation search should pursue the possibility that the 4th field is a better interpretation of the word. The main impact … is to reduce mis-adaption, and it is not used as a strong hint to make the substitution.”<link>
My personal theory is that Tesseract uses a confidence measure that it comes up with for the Unicode values it assigns to every glyph that it identifies, to decide whether or not to make the substitution. - Always substitute B for A.
The only time I used this value was when I wanted to remove all ligatures and long-s characters from the OCR results and replace them with their modern equivalents. (I did this because or dictionaries had no ligature or long-s characters, and so were not correcting words.)
The .unicharambigs file must end with a blank line (/n) at the bottom of the file.
Dictionary Files:
Dictionary files are used by Tesseract during the OCR process to help it determine if the string of characters it has identified as a word is correct. My theory is that if the confidence that Tesseract has in the characters in a word is sufficiently low so that changing these characters will cause the “word” to be changed into something that exists in the dictionary, Tesseract will make the correction. Otherwise it won’t do anything.
Tesseract’s dictionary files are in the form of DAWG files: Directed Acyclic Word Graphs. You can turn any word list into a DAWG file using Tesseract’s wordlist2dawg utility. The word list files must be .txt files with one word per line.
There are several different types of DAWG files and each is optional so you can create only the ones you want, or none at all. We have only used 2 with eMOP:
<lang>.word-dawg:
A dawg made from dictionary words from the language.
<lang>.freq-dawg:
A dawg made from the most frequent words which would have gone into word-dawg.
Any DAWG file must contain at least one entry. If you have a word in both lists it should be treated as a frequent word, so really there’s no advantage to it, and it just makes your word-dawg file larger.
My belief is that the dictionary files work in the same way as the unicharambigs above: If Tesseract’s confidence level in certain characters is low enough, and changing those characters would result in a dictionary word, then the change is made. However, it’s possible for Tesseract to “over correct” changing correctly spelled words into incorrectly spelled. One example I saw was changing “mee:” into “meet”. Both ‘mee’ and ‘meet’ are words in the dictionary
It’s important to include variant spellings and syncope word forms in the DAWG files in which the corresponding words occur. Words in the freq-dawg file are weighted higher than those in the word-dawg file. Having the variant spellings of a freq-dawg entry in the word-dawg file could cause Tesseract to change those variantly spelled words into the form found in the freq-dawg file.
Creating and Un-packing DAWGs:
Tesseract includes a utility for creating a DAWG file from a text file containing one word per line. The command is:
wordlist2dawg words-list.txt emop.word-dawg emop.unicharset
&
wordlist2dawg frequent-words-list.txt emop.freq-dawg emop.unicharset
NOTE that the unicharset file created for a language is used to contruct the DAWG files. That means that it MAY mean that the DAWG files will need to be rebuilt after any change to the unicharset file. This also means that creating the dictionary files should be done at the end of the training process.
Likewise, it is possible to take a DAWG file and convert it back to a text file word-list using the dawg2wordlist tool.
Carriage Return vs Line Feed
It is very important to note the Tesseract requires that Line Feed (LF) characters are used at the end of each line in the word-list text files used to create the DAWGs. These characters are invisible so determining that you’re using the right one can be difficult, but most text editors should provide some way of controlling this. Generally the default is Carriage Return (CR) in Mac, LF in UNIX, and CRLF in Windows.
On my Mac I use TextWrangler as my basic text editor. In any editing window you can see what encoding is being used in a bar at the bottom of the window. The default on a Mac is “Classic Mac (CR)”. This is a pull-down menu so you can change it here to “UNIX (LF)”. Don’t forget to resave.
Dictionary Sensitivity
It is possible to manipulate the dictionary’s sensitivity or the confidence that Tesseract should have in a dictionary word before making a change. Two variables are available to do this:
language_model_penalty_non_dict_word &
language_model_penalty_non_freq_dict_word
I am not entirely sure how these work and haven’t been able to find any good or clear documentation about them. The default values for these in the code are .15 and .1 respectively. I do know that increasing the number for these (to say .3 and .2 respectively) increases the sensitivity of the dictionary.
To set new values for these variables you will need to create a config file<link> and specify it’s use when running Tesseract on an image.
Config File:
In Tesseract, if you want to change the default value of a variable, then you must
- create a config file,
- include the variable with a new value, and
- specify that Tessearct should use that config file while processing an image.
1) Like all Tesseract files used while processing, the config file you create must be put in the same tessdata/ folder that you put the <lang>.traineddata file you create. You can name this file anything you want since you will have to call it specifically when you initiate a run of Tesseract. The config file is a simple text file containing one variable/value pair per line (probably ending with a UNIX LF).
2) I have come across several variables that can be included in the config file and these apparently change every time a new version of Tesseract is released, so there is no documentation about this. Here’s a list of them along with their default values.
- language_model_penalty_non_dict_word .1
language_model_penalty_non_freq_dict_word .15
These are used to change the confidence in the words contained in the DAWG files of the dictionary. Increasing the number increases the confidence. I don’t know what values are legal, but I’ve seen as low as .01 and as high as .95. - ClassPrunerThreshold 299
I’m honestly not sure this is a config file variable or if it goes somewhere else, however, I read in the FAQ that lowering this value (to say 200) will also increase the sensitivity of the dictionary, but also increases processing time. That’s not an option for eMOP with 45 million pages to scan. - enable_new_segsearch 0
Setting this variable to 1 causes Tesseract to use “the new SegSearch algorithm.” I don’t know what that is or what it does, but Nick White mentioned it in a post to the Tesseract Google Group on 10/2/12, and that he got improved results with it.
3) Specify a config file to use when you call issue the tesseract command. There are several gotchas related to this:
- The config file you created must be located in the directory from which you issue the tesseract command, or you must also provide a path name.
- You must include the extension of the config file when invoking it. In this case “config.txt”.
- The config file you are using with Tesseract come after the language you specify in the command with the –l switch.
tesseract <infile>.tif <outfile> -l emop config.txt
hOCR Otupt:
Non-text output is also possible with Tesseract and comes in an XML-like HTML format. You can specify this output format with another line in the config file.
- tessedit_create_hocr T
The default for the latest version of Tesseract (3.02.02 as of July 1, 2013) is to enclose each word in a <span> that includes attributes for each word’s number (@id), bounding box coordinates, and the confidence measure for the whole word (@title=’bbox A B C D; x_wconf E’).
You can either have Tesseract output as text or as hOCR, but not both at the same time. That requires two runs of Tesseract for each document being OCRed. Our plan is to output as hOCR and then use a script or XSLT to convert the output to text and/or to an XML format that we also need to emulate for ingestion into the Typewright tool. I will release that code when it’s available.

1 comments
Faster way of getting hOCR
Hi Matt. You mention at the end that getting text and hOCR from Tesseract output requires two runs of Tesseract, which would be unfortunate when you're dealing with the large volume of text you are. Happily that isn't really needed though; if you use the API to write a simple program you can the GetUTF8Text and GetHOCRText functions one after the other after the main recognition has finished, which would halve the time you're spending on Tesseract, which would be good indeed! There are basic API examples on the Tesseract wiki at http://code.google.com/p/tesseract-ocr/wiki/APIExample